
Artikelreihe
Dies ist der vierte von vier Artikeln, die verschiedene Aspekte der Auslieferung von Hilla-Anwendungen in Produktion beschreiben:
- Teil 1: Production-Build
- Teil 2: Docker-Images
- Teil 3: CI/CD
- Teil 4: Serverless Deployment
Serverless Deployment
Ein Production-Build einer Hilla-Anwendung als ausführbare JAR-Datei oder als Native Image zeichnet sich durch folgende Eigenschaften aus:
- Als Docker-Container können sie schnell und flexibel in Container-Umgebungen zum Einsatz kommen.
- Als Native Image oder als optimierte JAR-Datei kann die Hilla-Anwendung sehr schnell starten.
- Insbesondere als Native Image hat die Hilla-Anwendung einen geringen Speicherverbrauch.
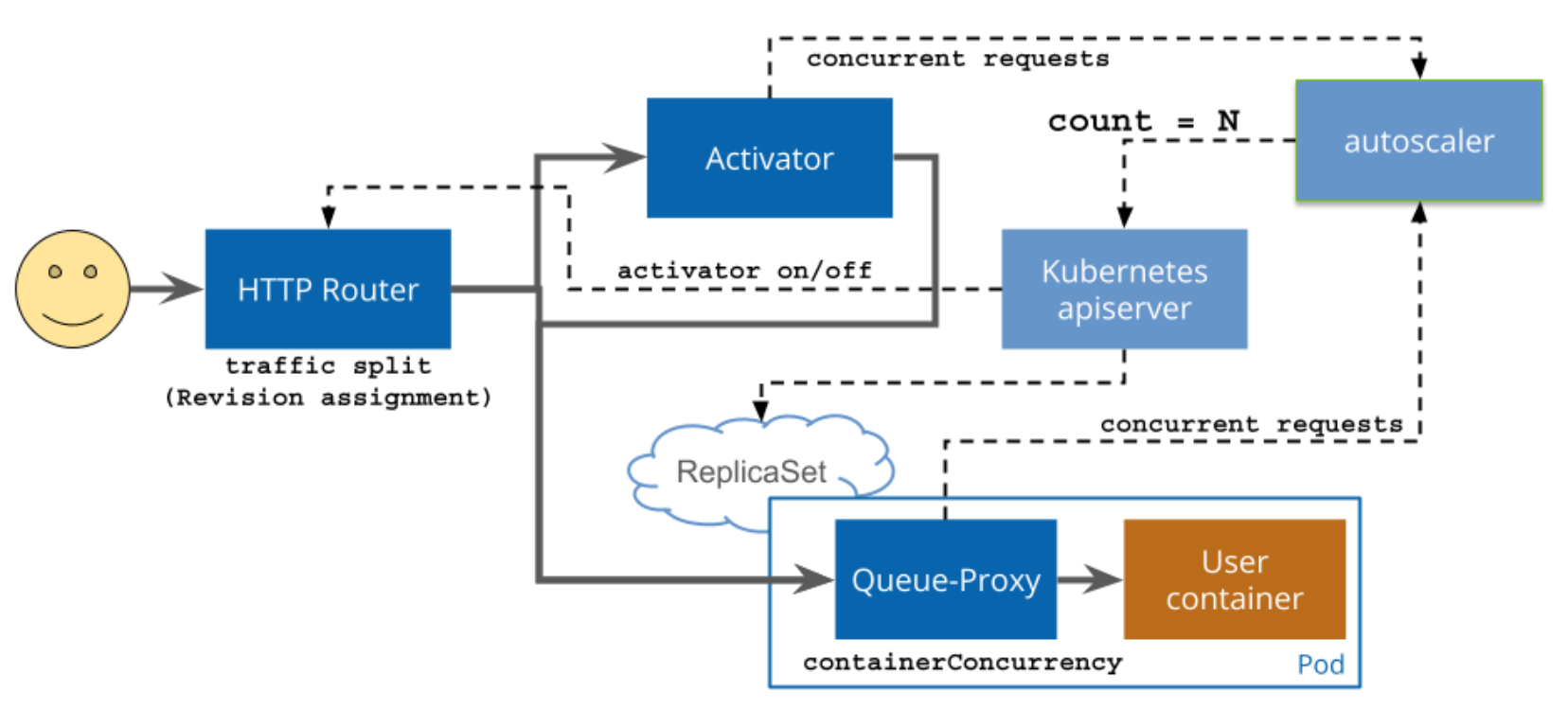
Darüber hinaus sind Hilla-Anwendungen standardmäßig zustandslos. All diese Eigenschaften tragen dazu bei, dass Hilla-Anwendungen sehr gut skalierbar sind. In Kubernetes-Umgebungen kann für diese Art der Skalierung zum Beispiel ein Horizontal Pod Autoscaler in Verbindung mit einem klassischen Deployment verwendet werden. Alternativ kann auch das so genannte Serverless Deployment zum Einsatz kommen. Bei dieser Form des Deployments werden die für das Deployment und die Skalierung erforderlichen Ressourcen und Konfigurationen noch weiter abstrahiert. Dies führt zu einer vereinfachten und kompakten Konfiguration. Knative ist ein Framework, das diese Art von Deployments in Kubernetes-Umgebungen mit Knative Serving unterstützt. Die nachfolgende Grafik zeigt den Ablauf einer Anfrage von einem Anwender bis zu einer Anwendung, die mit Knative Serving bereitgestellt wird:
Quelle: https://knative.dev/docs/serving/request-flow/
Der Activator erkennt bei eingehenden Anfragen, ob die Anwendung derzeit ausgeführt wird und initiiert ggf. den Start. Der Autoscaler überprüft, ob die Anzahl an Pods, die derzeit für eine Anwendung ausgeführt werden, zur Menge der Anfragen passen. Der Queue-Proxy puffert eingehende Anfragen, bis sie an einen verfügbaren Pod weitergegeben werden können.
Die nachfolgende YAML-Datei zeigt eine Konfiguration für ein Serverless Deployment einer Hilla-Anwendung, deren Production-Build als Docker-Image vorliegt:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hilla-production-build-serverless
spec:
template:
spec:
containers:
- image: corporate.registry.example.com/hilla-production-build:1.0.0
Skalierung
Bei Knative kann der so genannte Knative Pod Autoscaler (KPA) für die Skalierung von Anwendungen eingesetzt werden. Eine besondere Funktion des KPA ist Scale to Zero. Ist diese Funktion aktiv, kann Knative die Pods einer Anwendung vollständig herunterfahren, wenn die Anwendung innerhalb eines konfigurierbaren Zeitraums keinen eingehenden Traffic mehr aufweist. Diese Funktion kann dabei helfen, Kosten und Energie beim Betrieb einer Hilla-Anwendung zu sparen und einen Kubernetes-Cluster effizienter auszulasten.
Erhält die Anwendung viel oder schwankenden Traffic, kann der KPA die Anwendung natürlich auch nach oben oder unten skalieren und automatisch weitere Pods starten oder nicht mehr erforderliche Pods wieder beenden. Damit der KPA diese automatische Skalierung einer Anwendung durchführen kann, muss die zuvor gezeigte Konfiguration erweitert werden. Eine sehr einfache Form der Skalierung kann dabei anhand der Eigenschaft containerConcurrency erreicht werden:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hilla-production-build-serverless
spec:
template:
spec:
containerConcurrency: 300
containers:
- image: corporate.registry.example.com/hilla-production-build:1.0.0
Diese Eigenschaft steuert, wie viele eingehende Aufrufe ein Pod maximal verarbeiten kann, bevor ein weiterer Pod gestartet wird. Alternativ oder ergänzend zu diesem harten Limit kann auch eine Skalierung auf Basis der Auslastung einzelner Pods konfiguriert werden. Hierfür können verschiedene Metriken verwendet werden. Der KPA unterstützt hier concurrency und rps (Requests per seconds). Wer die Skalierung an der CPU- oder Speicherauslastung ausrichten möchte, kann Knative auch in Verbindung mit dem Horizontal Pod Autoscaler (HPA) verwenden, muss dann aber auf die Scale-to-Zero-Funktionalität verzichten (siehe dazu Supported Autoscaler types). Die nachfolgende Konfiguration verwendet die Metrik concurrency mit einem Zielwert:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hilla-production-build-serverless
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "concurrency"
autoscaling.knative.dev/target: "300"
spec:
containers:
- image: corporate.registry.example.com/hilla-production-build:1.0.0
Diese Konfiguration beschreibt ein weiches Limit von maximal 300 gleichzeitigen Verbindungen zu einem Pod. Dieses Limit kann bei kurzzeitigen Spitzen auch überschritten werden.
Liveness- und Readiness-Probes
Eine sinnvolle Erweiterung der gezeigten Deployment-Konfiguration ist die Ergänzung einer Liveness- und Readiness-Probe. Mit Hilfe dieser Probes kann Knative erkennen, ob ein Pod erfolgreich gestartet wurde und ob ein Pod noch korrekt ausgeführt wird. Diese Informationen sind wichtig, damit Knative die erforderliche Anzahl an Pods starten und ausführen kann, die aufgrund der Konfiguration für die Skalierung erforderlich sind.
Da Hilla-Anwendungen auf Spring Boot basieren, können die erforderlichen Endpunkte für die Liveness- und Readiness-Probes mit Hilfe des Projektes Actuator realisiert werden. Dazu muss Actuator zunächst als zusätzliche Dependency in der pom.xml hinzugefügt werden:
<!-- ... -->
<dependencies>
<!-- ... -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- ... -->
</dependencies>
<!-- ... -->
Anschließend kann der passende Health-Endpunkt in der application.properties aktiviert werden:
# Disable all default endpoints
management.endpoints.enabled-by-default=false
# Enable health endpoint
management.endpoint.health.enabled=true
# Probes are automatically enabled if the app runs in a Kubernetes environment, or manually like this
management.endpoint.health.probes.enabled=true
Für Liveness- und Readiness-Probes stehen spezielle Endpunkte unterhalb des Health-Endpunktes zur Verfügung.
Ein GET-Request auf den Pfad /actuator/health/liveness der Hilla-Anwendung ruft den Liveness-Endpunkt auf. Aus Sicht von Spring Boot Actuator ist eine Anwendung live sobald der ApplicationContext gestartet und aktualisiert wurde. In diesem Fall erhält man folgende Response mit Status-Code 200:
{ "status" : "UP" }
Ist die Anwendung noch nicht live oder befindet sie sich in einem fehlerhaften Zustand, erhält man eine Response mit dem Status-Code 503:
{ "status" : "DOWN" }
Ein GET-Request auf den Pfad /actuator/health/readiness der Hilla-Anwendung ruft den Readiness-Endpunkt auf. Aus Sicht von Spring Boot Actuator ist eine Anwendung ready sobald sie in der Lage ist, eingehende Anfragen entgegenzunehmen und zu verarbeiten. In diesem Fall erhält man folgende Response mit Status-Code 200:
{ "status" : "UP" }
Kann die Anwendung noch keine eingehenden Anfragen entgegennehmen und verarbeiten, erhält man eine Response mit dem Status-Code 503:
{ "status" : "OUT_OF_SERVICE" }
Dies kann beispielsweise passieren, wenn die Anwendung schon live ist, aber im Rahmen des Startvorgangs noch Aufgaben durch den Spring Boot CommandLineRunner oder ApplicationRunner ausgeführt werden.
Zusätzlichen zu diesen Standard-Indikatoren können bei Bedarf auch individuelle Health-Indikatoren implementiert werden.
Für die Readiness- und Liveness-Probe von Knative kann der Health-Endpunkt wie folgt verwendet werden:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hilla-production-build-serverless
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "concurrency"
autoscaling.knative.dev/target: "300"
spec:
containers:
- image: corporate.registry.example.com/hilla-production-build:1.0.0
readinessProbe:
httpGet:
path: /health/readiness
port: 8080
scheme: HTTP
periodSeconds: 5
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
livenessProbe:
httpGet:
path: /health/liveness
port: 8080
scheme: HTTP
periodSeconds: 5
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 6
Die Readiness-Probe überprüft, ob der Health-Endpunkt nach dem Start des Pods über einen Zeitraum von 5 Sekunden (periodSeconds) innerhalb von 1 Sekunde (timeoutSeconds) mit dem Status UP und dem Status-Code 200 antwortet. Dieser Test wird maximal 3 Mal (failureThreshold) wiederholt und schlägt somit nach maximal 15 Sekunden endgültig fehl. Die Liveness-Probe führt den gleichen Test dauerhaft aus, nachdem der Pod den Status Ready erreicht hat. Im Unterschied zur Readiness-Probe wird bei der Liveness-Probe ein höherer failureThreshold konfiguriert. Antwortet der Health-Endpunkt über einen Zeitraum von maximal 30 Sekunden nicht ein einziges Mal innerhalb von 1 Sekunde mit dem Status UP und dem Status-Code 200, wird der Pod beendet, weil davon auszugehen ist, dass die Anwendung nicht mehr korrekt ausgeführt wird.
Fazit
Serverless Deployments mit Scale-to-Zero-Funktionalität ermöglichen einen effizienten und skalierbaren Betrieb von Anwendungen in Container-Umgebungen. Knative Serving bietet hierfür eine einfache Art der Deployment-Konfiguration. Zustandslose Hilla-Anwendungen eignen sich hervorragend für diese Art von Deployments, insbesondere als Production-Build in Form einer ausführbaren JAR-Datei oder als Native Image.